








׃��ϵ���Ķ��x�����ڔ��������еđ���
����
ʲô��׃��ϵ����
��֪���ᣬ���҂�ՄՓ�����ĕr����������һ�����������׃��ϵ�������@��� ����ͦ���I�ģ������H�Ͼ����Á�����һ�M�������xɢ�̶ȵ�һ��ָ�ˡ������f�������Ԏ����҂��˽��@Щ����֮�g�IJ�ж������һ�£��������һ���O�����еĴ��е�С��׃��ϵ�����ܸ��V���@Щ�O����С֮�g�IJ�e�����ж����@��
׃��ϵ������ôӋ������ģ�
��ô���@��׃��ϵ����������ô��������أ��䌍����߀ͦ���εġ����ȣ�����Ҫ֪���@�M�����Ę˜ʲҲ����ÿ����ֵ�cƽ��ֵ֮�g����ƽ�������_���ĽY����Ȼ�����ٰ��@���˜ʲ�����@�M������ƽ�������@�ӵõ��ĽY������׃��ϵ���ˡ��ù�ʽ��ʾ��Ԓ������CV = �� / �̣����ЦҴ���˜ʲ�̄t��ƽ�������Dz����X�����c�����˕r����ʳ�Vһ�������ĸ��X��
��ʲô�҂���Ҫʹ��׃��ϵ����
�@�r������ܕ����ˣ�����Ȼ�ѽ����˘˜ʲ��ɶ߀Ҫ�む׃��ϵ�����������Æ��}���@������Еr��⿴�˜ʲ�߀������ȫ������┵������r������ɽM�����������Ę˜ʲ������ͬ�������ƽ��ֵ���ܴ���ô�@�ɽM�����Č��H������r�͕���ȫ��ͬ���@�r��׃��ϵ���������È��ˣ���������]����ƽ��ֵ��Ӱ푣��܉���ʴ_�ط�ӳ�������g������׃�����ȡ������DZ��^�ɂ���ͬ��С�ij������~�Ĕ���׃��һ�ӣ�ֱ�ӱȔ������ܲ�̫��ƽ��������҂�����ÿƽ����ˮ�����ж��ٗl�~���Ǿ������x�ˡ�
�ڌ��H�У�׃��ϵ������Щ���È�����
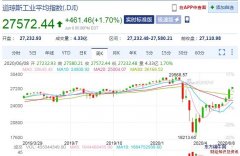
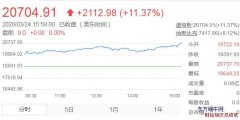
�f���@������϶���֪�����ڬF�������У�׃��ϵ�������ܸ�ɶ���䌍������;�dz��V���������f���ڽ����I��Ͷ�Y�ߕ�����׃��ϵ�����u��Ͷ�Y�M�ϵ��L�Uˮƽ�����t�W�о��У��о��ˆT����ͨ�^������������ָ�˵�׃��ϵ�����Д�ij�N�ί�������Ч����Σ����������w����ِ�У��̾�Ҳ�������\�ӆT�ɿ���׃��ϵ�����ƶ�Ӗ��Ӌ������֮���oՓ���ڿƌW�о�߀���ճ��Q���^���У�ֻҪ�漰���������g��ԵĿ�����׃��ϵ������һ���dz����õĹ��ߡ�
������_���x׃��ϵ����
��Ȼ�����mȻ׃��ϵ���ܺ��ã����҂�Ҳ����äĿ��ه�����������κνyӋָ�˶���������ԡ����箔�����������O��ֵ������ֵ���r��׃��ϵ�����ܕ�������sС���Ķ�Ӱ푵��҂����Дࡣ��ˣ���ʹ��׃��ϵ���M�Д��������r��߀��Ҫ�Y�������yӋ��һ�]������Ҫ�_���������|���ɿ����@��������r���HҪ�Pע�{�ϵı�����߀�ñ��Cʳ�����rһ����Ҫ��
���Y
���ā��f��׃��ϵ����һ���dz����õĔ����������ߣ����܉�����҂����õ�����ͽ�ጔ�������Ĺ��¡�ͨ�^�����\���@һָ�ˣ��҂����ԏď��s��׃����Ϣ�������្���Ѓrֵ��֪�R�c����Q���ṩ��������֧�֡����^�e���ˣ����������ʳ��Ҫ�C�Ͽ��]���N����һ�ӣ��ڔ����������^����ҲҪ�`���\�ö�N����Ŷ��
Q&A
����׃��ϵ���m����������͵Ĕ����
- �𣺴������r�����m�õģ���������Щ�]�����_ƽ��ֵ���x�Ĕ�����ͣ�����׃�������t���m�á�
��������ҵĔ��������Ю���ֵ����Ӱ�׃��ϵ���ĽY���
- �𣺴_������Ӱ푡����׃��ϵ�����ژ˜ʲ�Ӌ����������˜ʲ����ֵ�dz����С���ˣ���̎�����Ю���ֵ�Ĕ���ǰ����Ȍ����M���m��̎����
��������׃��ϵ���⣬߀����Щ���õĶ���������ɢ�̶ȵķ�����
- �𣺳�Ҋ��߀�����ķ�λ��(IQR)���O��(Range)�ȡ�ÿ�N�������������c���m�È������x����m�ķ���ȡ�Q�ھ��w���������ԡ�